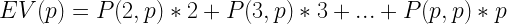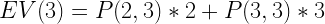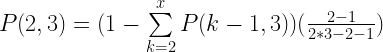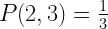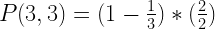Another week, another riddler. This one comes from Barbra Yew:
There are eight three-digit numbers — each belongs in a row of the table below, with one digit per cell. The products of the three digits of each number are shown in the rightmost column. Meanwhile, the products of the digits in the hundreds, tens, and ones places, respectively, are shown in the bottom row.

Can you find all eight three-digit numbers and complete the table? It’s a bit of a mystery, but I’m sure you have it within you to hunt down the answer!
One basic way of finding the answer would be to brute force each possible number in each empty cell. This would require roughly 10^24th attempts which is much too large.
To narrow the searchspace we can either use the constraint that the numbers column-wise have to multiply together to equal the huge bottom number or the numbers row-wise have to multiply together to equal the much smaller side number. It becomes much easier if we use the row-wise constraint.
To do this we take the target number (294 in the first row) and find it’s factors. Since we know the numbers have to be one digit, we throw out any that are larger than 9. Then we find a set of 3 of these factors that multiplies together to equal the target number (7, 7, 6 to get 294). We do this for each row and see if the column relationship works. If it doesn’t we shuffle the rows (7, 6, 7 or 6, 7, 7) to see if that helps.
By utilizing the computer and python I was able to find an answer in a few minutes of searching. The answer:
[7, 7, 6]
[9, 8, 3]
[9, 5, 3]
[7, 2, 7]
[8, 2, 7]
[7, 4, 3]
[5, 7, 7]
[8, 5, 1]
The code can be found here